
Using AI and Amazon Rekognition to automate your website QA and visual testing

Introduction
As a company, we hold website maintenance contracts with multiple clients. One of our core responsibilities in this capacity is to continually monitor their websites for any potential issues, including uptime, SEO, accessibility, and performance. Although we have automated much of this process through the use of various tools, there is one particular aspect that remains difficult to automate: visual testing. In this area, our quality assurance team must manually inspect each webpage to ensure that everything appears functional and properly ordered.
This article details our solution to the aforementioned challenge by leveraging image recognition technology. Our approach involved training AWS Rekognition to "recognize" distinct webpages, which we subsequently integrated into an infrastructure that automatically conducts routine checks at predetermined intervals. The results generated by the model are conveyed to our QA team, who can then provide feedback on any detected errors. This feedback is then used to further enhance the machine learning model, resulting in an ongoing cycle of continuous improvement.
The Problem
As a website maintenance partner for our clients, we undertake a diverse range of ongoing activities, which include:
ADA Compliance: We address website issues related to color contrast, image labeling, form field functionality, JavaScript usage, and font size adjustments to improve ADA compliance.
SEO Enhancements: We can optimize website pages by adding appropriate titles, meta-tags, and URL naming conventions.
Performance Monitoring: Our team regularly scans websites for performance issues and provides quarterly reporting. Upon identifying any issues, we prioritize and authorize necessary changes.
Security: We offer regular website monitoring to identify and resolve any security threats as reported by monitoring tools.
Uptime Monitoring: We use tools such as Pingdom to ensure regular website uptime and to identify any downtime, which is then promptly notified.
To aid us in the continuous monitoring process, we rely on a variety of tools. For instance, we utilize products like Statuscake to automatically track uptime and performance metrics. Additionally, tools like Siteimprove and Accessibe allow us to promptly identify and address any accessibility concerns. Similarly, real-time security tracking tools are employed to ensure the websites are secure. Furthermore, we have developed proprietary in-house tools to monitor SEO issues and respond promptly to any detected problems.
Automating the visual testing of a website is a formidable challenge due to the constant updates made by marketing teams. A website update doesn't necessarily mean that it's "broken". Here are a few examples that illustrate this point:
The marketing team replaces the main image in the homepage hero section.
A new news article is published and displayed on the homepage.
The copy for a product description on the homepage is altered.
It's evident that none of these examples indicate a "broken" webpage. However, if we were to automate the process of identifying changes by comparing the current HTML of a webpage with a prior version, we would observe differences in the HTML structure. As a result, the tool could generate a "False Positive" and wrongly indicate that the webpage is broken when it's actually not.
Why Image Recognition?
Using image recognition for website visual testing can offer several advantages over traditional testing methods, particularly when it comes to detecting visual discrepancies and improving the overall user experience. Some reasons to consider using image recognition for website visual testing include:
Faster detection of visual issues: Image recognition can quickly and automatically identify layout discrepancies, incorrect font rendering, color issues, or broken images, which might be difficult to spot through manual testing or traditional functional testing methods.
Comprehensive testing: Image recognition allows for more extensive testing across multiple devices, screen resolutions, and browsers, ensuring that your website looks and performs consistently for a wider range of users.
Objectivity: Automated visual testing using image recognition eliminates human subjectivity, reducing the chances of human error and inconsistencies in test results.
Time and cost savings: Automating the visual testing process can significantly reduce the time and effort required for manual testing, freeing up your team to focus on other important tasks and speeding up the overall development process.
Improved collaboration: Visual testing results can be easily shared with team members, allowing developers and designers to collaborate more effectively to resolve issues and maintain a consistent visual appearance across the website.
Historical tracking: Automated visual testing using image recognition allows you to store and track historical test results, enabling you to identify trends, recurring issues, or improvements in your website's visual appearance over time.
Integration with CI/CD pipelines: Automated visual testing can be easily integrated into your existing continuous integration/continuous delivery (CI/CD) pipeline, helping to ensure that your website's visual appearance remains consistent throughout the development process.
It's important to note that image recognition might not be suitable for all types of visual testing, particularly when pixel-perfect accuracy is required. In such cases, dedicated image comparison libraries or tools might be a better fit. However, using image recognition for website visual testing can still be a valuable addition to your testing arsenal, especially when combined with other testing methods.
Using AWS Rekognition
AWS Rekognition can be used for website visual testing by leveraging its capabilities in image and video analysis. By combining Rekognition with other AWS services, you can create a robust and automated visual testing pipeline for your website. Here's a high-level overview of how you can use AWS Rekognition for website visual testing:
Capture screenshots: Use a headless browser (e.g., Puppeteer, Selenium, or Playwright) to take screenshots of your website at different breakpoints, resolutions, and on various devices.
Store screenshots: Upload the captured screenshots to Amazon S3, an object storage service, and organize them in a structured manner (e.g., by test case, device, or resolution).
Create a baseline: Select a set of "golden" screenshots as your baseline. These are the screenshots that represent the expected appearance of your website. You can store these baseline images in a separate S3 bucket or a dedicated folder within the same bucket.
Train a “Custom Label” model: Custom Labels is a feature of Amazon Rekognition that allows you to train custom machine learning models for detecting objects and scenes in images, tailored to your specific requirements. Unlike the pre-trained models that AWS Rekognition provides out of the box, Custom Labels enables you to create a model that recognizes objects, scenes, or concepts that are unique to your particular use case.
Analyze results: Process the results from the Rekognition API to identify any visual differences or discrepancies between the current screenshot and the results returned by the model. You can use AWS Lambda or another serverless compute service to analyze the results and determine whether the differences are significant enough to be considered a failure.
Report findings: Integrate the visual testing results into your continuous integration/continuous delivery (CI/CD) pipeline. You can use services like AWS CodePipeline or Jenkins to manage the testing process. Notify your development team of any issues or discrepancies through communication tools like Slack or email.
Store historical data: Maintain a record of historical test results, including the images and the analysis data, in an Amazon S3 bucket or Amazon DynamoDB. This can be useful for tracking visual changes over time and identifying recurring issues.
By following these steps, you can use AWS Rekognition and other AWS services to build an effective website visual testing solution.
A Sample Case Study
One of our customers is “History Colorado”. History Colorado [https://www.historycolorado.org] is an agency of the State of Colorado under the Department of Higher Education. They are the trusted leader in helping people understand what it means to be a Coloradan—by sharing powerful stories, honoring our state’s treasured memories, and creating vibrant communities. We are the website maintenance partner responsible for the site’s performance, SEO and uptime.

In the following sections, we will guide you through the entire process of training AWS Rekognition to recognize the home page, capturing regular screenshots, submitting them to the model, forwarding the model's results to our QA team, and continuously training the model for improved accuracy.
Training AWS Rekognition
The first step involves training AWS Rekognition to identify the History Colorado homepage image mentioned previously. Here's a summary of the process:
Utilize the Browserstack API to produce hundreds of screenshots on various devices.
Save these images in an S3 bucket.
Process the images using an image slicer, which randomly divides each image into several parts.
Transfer these cropped images (hundreds in total) to a folder in AWS Rekognition Custom Model.
Train AWS Rekognition using these images, associating them with a specific label.
Leveraging the Browserstack API
BrowserStack is a cloud-based platform for cross-browser testing, granting developers and QA teams immediate access to more than 2,000 real devices and browsers for examining their web applications. A notable feature of BrowserStack is its Screenshot API, which enables users to programmatically capture web page screenshots on various browsers and devices.
The Screenshot API allows developers to automate the screenshot capture process across different browsers and devices, removing the necessity for manual testing. This API offers a user-friendly RESTful interface to obtain screenshots in either PNG or JPEG format.
Here's an example of a request for the Screenshots API:
The API will return a response as follows:
Storing the images in an S3 bucket
A Python project has been developed to manage Browserstack APIs, image processing, and image uploads to an AWS S3 bucket. The Python requests library is a popular choice for executing HTTP requests in Python, enabling developers to communicate with web services and APIs through sending HTTP requests and receiving responses. The requests library is utilized to call the Browserstack API and obtain the necessary screenshot responses.
The images are subsequently uploaded to AWS S3 buckets using the Python boto3 SDK. Boto3 is a Python library that offers a low-level interface to Amazon Web Services (AWS), enabling developers to create Python code that interacts with AWS services such as Amazon S3, Amazon EC2, Amazon DynamoDB, and more. Furthermore, the boto3 SDK for AWS can be employed to save images from the API response into an S3 bucket.
Here is a sample code to upload image to S3 bucket through boto3 client.
Slicing the images
The screenshot images stored in the S3 bucket are subsequently processed using Python libraries like Numpy, PIL (Python Imaging Library), or OpenCV. You can configure the image cropping parameters, such as the desired number of images and minimum size. As a result, each image in the S3 bucket is divided into dozens of smaller images.
The screenshot images can be processed by Numpy as follows.
Training the Rekognition Model
Amazon Rekognition Custom Labels is a component of Amazon Rekognition that enables the development of bespoke machine learning models for object detection. Custom Labels allows you to create a specialized model for detecting particular objects within images and videos by utilizing your own annotated data.
A new Amazon Rekognition Custom Labels service project is established in the AWS Management Console. A dataset is generated using the screenshot images from the previously mentioned S3 bucket, utilizing the boto3 Rekognition client as described below.
The project model is subsequently trained on the dataset using the Boto3 client in a programmatic manner, as illustrated below.
Upon completing this training, we have successfully developed an Amazon Rekognition model capable of identifying the History Colorado homepage.
Automating the End-End Process
Once the Rekognition model is trained to recognize the History Colorado homepage, we create a process that regularly captures screenshots of the homepage and submits them to the model for evaluation. We then forward the model's results to our Quality Assurance team for manual assessment. The QA team's feedback is fed back into the Rekognition model, enabling continuous improvement over time.
The technical steps involved include the following:
Develop a Lambda function for capturing screenshots
Set up an EventBridge function to periodically trigger the Lambda function
Employ SNS to send the results via email
An AWS Lambda function to take screenshots
Amazon Web Services (AWS) offers AWS Lambda, a serverless computing service that enables you to execute code without managing servers or infrastructure. AWS Lambda operates on the principle of functions, which are code segments that can be executed in response to events or triggers.
AWS Lambda functions support various programming languages, including Node.js, Python, Java, Go, and more. Upon invoking a function, AWS Lambda allocates the required computing resources and executes the code.
Begin by creating a Lambda function in the AWS Console using the "Author from scratch" option and selecting Node.js as the runtime environment.
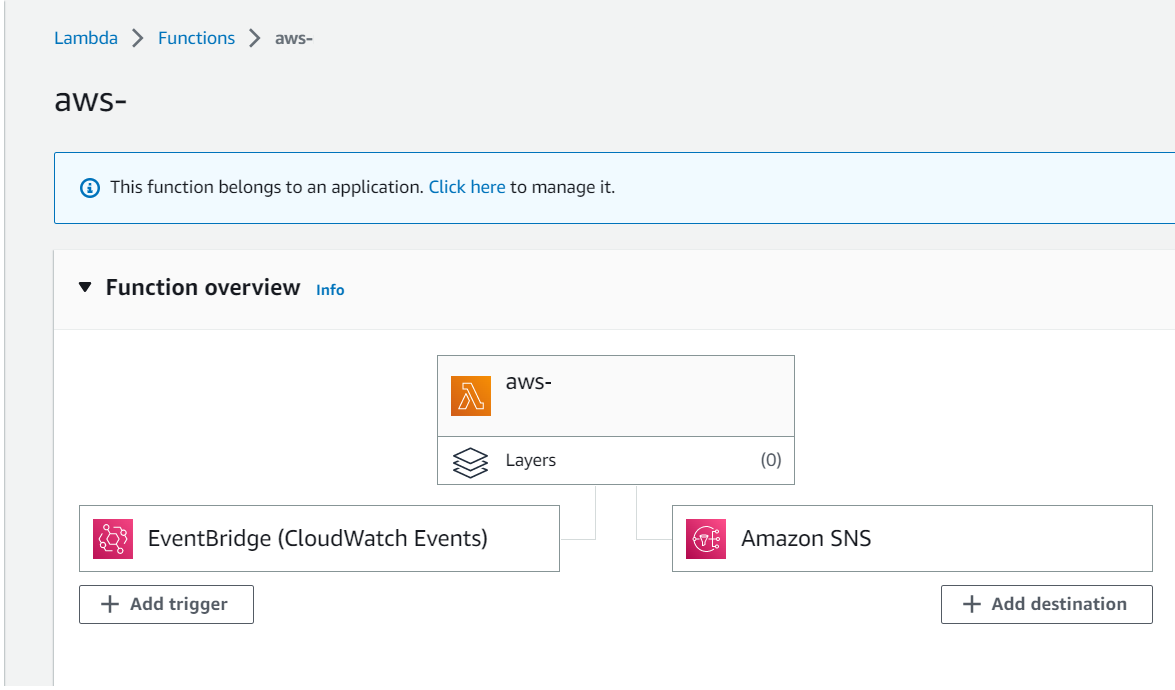
The NodeJS Project to Take Screenshots in the Lambda Function
Proceed by constructing the Node.js project, incorporating the chrome-aws-lambda and puppeteer npm packages.
The chrome-aws-lambda Node.js package supplies a version of the Google Chrome browser tailored for execution within an AWS Lambda function. Specifically designed for serverless environments, this Chrome version is headless, lacking a graphical user interface. It is intended for background operation, performing tasks such as web scraping, capturing screenshots, and conducting automated tests.
The Puppeteer Node.js library offers a high-level API to control a headless variant of the Google Chrome browser. This enables automating interactions with web pages and accomplishing tasks like web scraping, PDF generation, web application testing, and capturing screenshots.
In the following code snippet, a headless Chrome instance is launched using the Puppeteer library, navigates to a specified URL, and takes a screenshot of the page. The captured screenshots are then saved in the S3 bucket.
Compile the project and deploy it to the previously created Lambda function. To invoke the function, add an EventBridge event as a trigger, described next.
Amazon EventBridge
Amazon EventBridge is a serverless event bus service enabling real-time event routing between AWS services, SaaS applications, and custom applications using a publish/subscribe model. With Amazon EventBridge, you can establish rules to match incoming events and direct them to one or more targets, such as an AWS Lambda function, an Amazon SNS topic, an Amazon SQS queue, or a custom webhook.
Create a new EventBridge rule, scheduling it to invoke the previously described Lambda function (with the NodeJS code) every 12 hours, as demonstrated below.
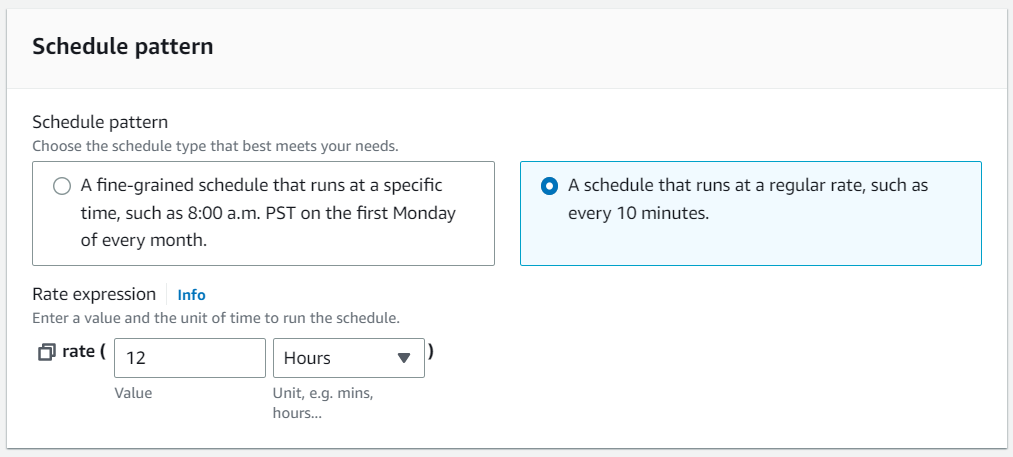
Amazon SNS
Amazon Simple Notification Service (SNS) is a comprehensive messaging solution provided by Amazon Web Services (AWS). This service enables the delivery of messages or alerts to a wide range of subscribers or endpoints, including email, SMS, mobile push notifications, and HTTP endpoints. To utilize this service, establish an SNS topic and connect it to the desired Lambda function destination.
By setting up the Lambda function destination and selecting Amazon SNS as the intended resource, the asynchronous output of the Lambda function gets directed to the specified location. This arrangement facilitates the sharing of Lambda function results via an SNS topic, which then disseminates the response to all its subscribers.
The notification email looks like this.
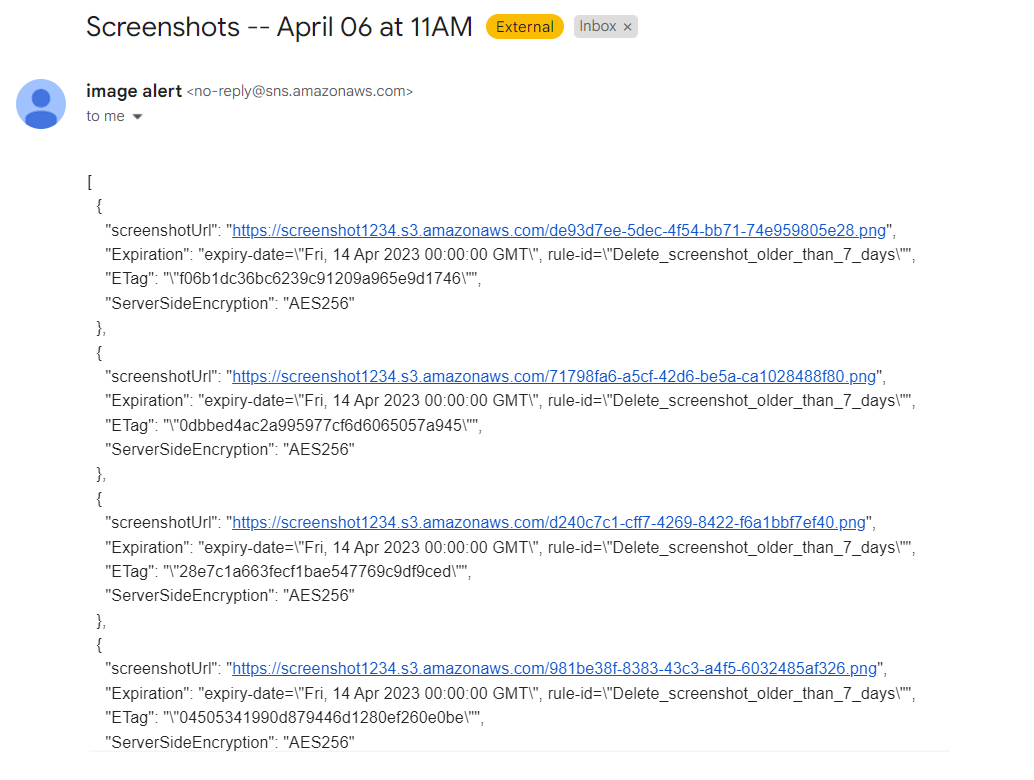
The generated screenshot URLs are subsequently categorized by the Rekognition model through the activation of an additional Lambda function. We can classify images from websites using the Boto3 detect_custom_labels method.
The results back from Rekognition looks like this

Once the response is received from the Rekognition model, the results are forwarded to the Quality Assurance (QA) Team for manual evaluation and comparison to ensure accuracy.
We have now implemented a service that periodically captures screenshots of the History Colorado homepage, forwards them to the Rekognition model for analysis, retrieves the results, and emails the outcome to the QA team for manual confirmation.
Some Sample Results
Below are some sample results from the Amazon Rekognition Model.
We sent the following images and got a 90% confidence output, indicating its a "True Positive"

We sent this second image and got a 0% Confidence result, indicating its a "True Negative"
Our work is ongoing and we are continuously refining and enhancing the model to achieve better results.
Summary
Building an image recognition system that utilizes ML ( machine learning ) can help automate your QA process and streamline your overall workflows significantly. Using AWS Rekognition , Lambda Function, Browserstack and other tools, we’ve been able to shorten the overall testing and troubleshooting time and effort for our team and our clients exponentially. While this may appear to be a highly technical endeavor at first, our insight post is the perfect starting point to help you gain a step by step; example driven insight to implement this innovative solution to automate web page visual testing for your website.